AI Cost Reduction Solutions
Dramatically reduce AI implementation costs while maintaining quality and performance
Book a Consultation
As organizations increasingly adopt AI technologies, managing the associated costs has become a critical concern. From API calls to computing resources, the expenses can quickly escalate, especially as usage scales. Our cost reduction solutions address this challenge head-on, providing strategies and tools to optimize AI expenditure without sacrificing quality or performance.
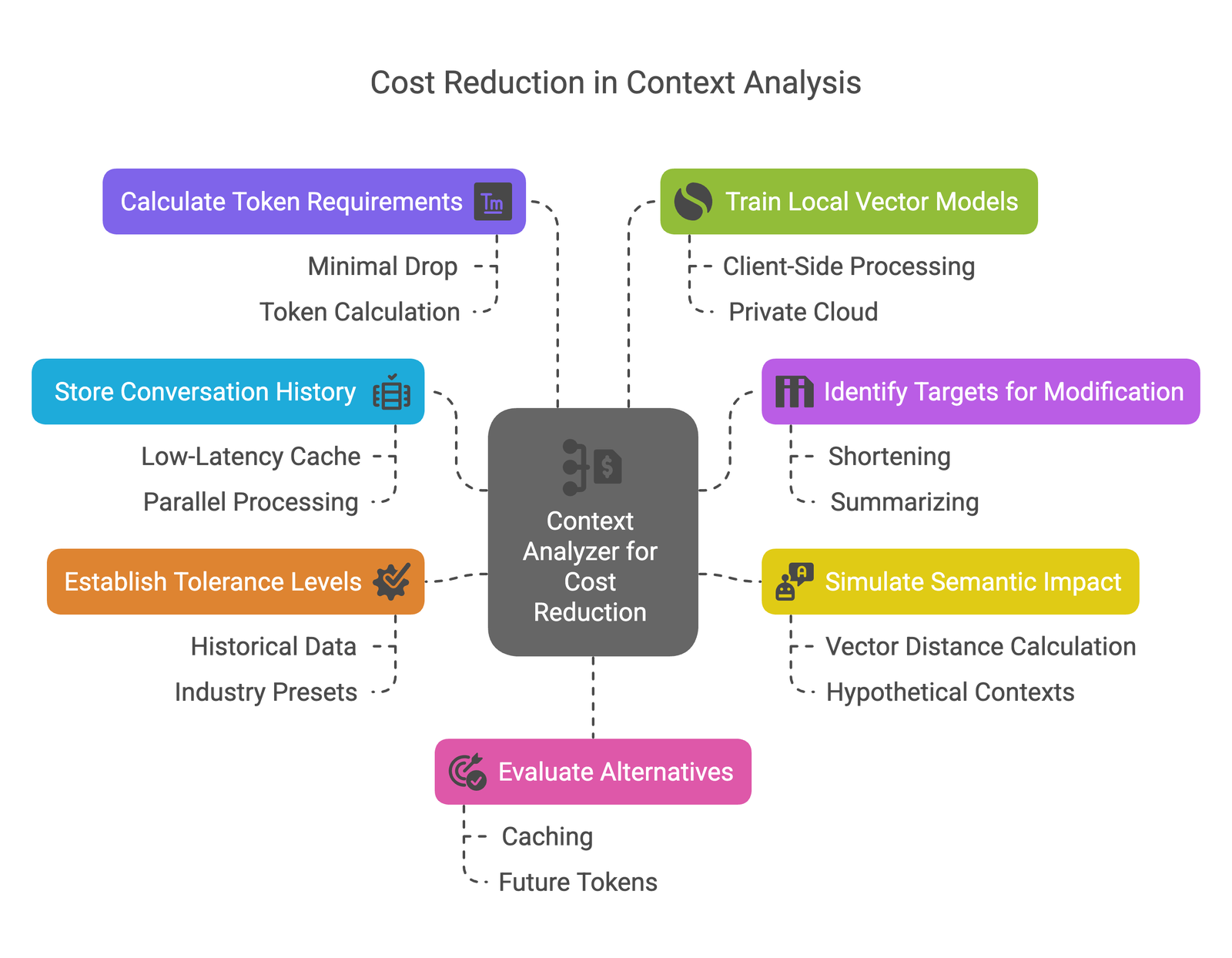
Our revolutionary Context Analyzer for Cost Reduction is at the heart of our cost optimization strategy. This sophisticated system analyzes conversations and context to identify opportunities for efficiency improvements without compromising semantic understanding.
Unlike basic token-cutting approaches, our system uses specialized embedding models to analyze how each block of text impacts the model's semantic understanding. By identifying which content is most crucial for maintaining context, we can intelligently optimize token usage while preserving the quality of responses.
The result? An average 81% reduction in token costs with only a 0.13% potential impact on output quality.
Precise calculation of token usage with minimal impact on performance through advanced token calculation techniques.
Efficient storage and retrieval of conversation history using low-latency caching and parallel processing.
Client-side processing capabilities and private cloud options to reduce dependency on costly external APIs.
Intelligent shortening and summarizing of content that preserves critical information.
Customizable tolerance settings based on historical data and industry-specific presets.
Prediction of how changes will affect understanding through vector distance calculation and hypothetical contexts.
Implementation of caching strategies and future token prediction to further reduce costs.
Our Conversion API allows seamless conversion between different AI model providers (OpenAI, Anthropic, Gemini), enabling you to choose the most cost-effective option for each specific task without changing your implementation.
We offer strategies for training and deploying local vector models that can handle certain tasks without requiring external API calls, significantly reducing ongoing operational costs.
Our advanced prompt caching system identifies repeated patterns and can serve cached responses for similar queries, eliminating unnecessary API calls and reducing latency.
For enterprises with specific requirements, we develop tailored cost optimization strategies that address your unique challenges and usage patterns.
Our cost reduction solutions have delivered substantial savings for organizations across various industries:
These savings aren't just temporary—they're sustainable improvements that continue to deliver value as your AI usage grows and evolves.
Our experts will analyze your current AI implementation and identify opportunities for significant cost savings without compromising performance. Contact us today to learn how we can help you optimize your AI expenditure.
Book a Consultation